Bạn đã bao giờ nghe đến “Web Crawler” hay “Crawling” trong SEO? Đây là một trong những yếu tố quan trọng liên quan trực tiếp đến quá trình xếp hạng bài viết của Google. Bài viết sau đây của Công Ty Quảng Cáo Marketing Online Limoseo sẽ chia sẻ các thông tin hữu ích và chi tiết nhất xung quanh “Crawling là gì” và Web Crawler hoạt động như thế nào để giúp bạn thực hiện SEO hiệu quả hơn nhé!
MỤC LỤC
1. Crawling là gì? Web crawler là gì?
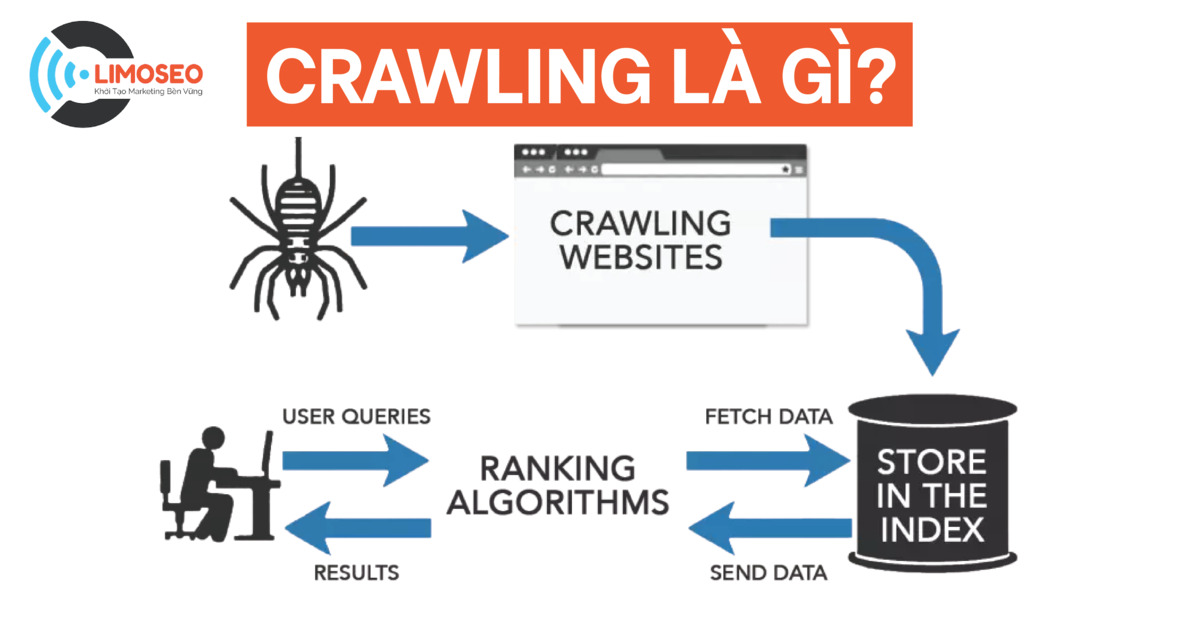
Crawling là quá trình khám phá và thu thập dữ liệu từ các trang web. Các công cụ tìm kiếm như Google (sử dụng web crawler), còn được gọi là spider hoặc bot, để duyệt theo cách thức có hệ thống trên web và tìm kiếm nội dung mới hoặc cập nhật để lập chỉ mục cho các bài viết. Dữ liệu mà web crawler thu thập được sẽ sử dụng cho quá trình lập chỉ mục và xếp hạng các trang.
Web Crawler là một bot thực hiện quá trình Crawling (thu thập dữ liệu) được đề cập ở trên và nó có nhiệm vụ tải xuống dữ liệu và lập chỉ mục cho tất cả các trang web, bài viết nó đi đến trên internet.
2. Tại sao Web Crawler quan trọng trong SEO?
Web crawler là rất quan trọng đối với SEO vì nó liên quan trực tiếp đến quá trình công cụ tìm kiếm phát hiện và lập chỉ mục các trang web. Nếu một trang không được crawling, nó sẽ không được lập chỉ mục và sẽ không xuất hiện trong kết quả tìm kiếm. Nếu không có web crawler, công cụ tìm kiếm sẽ không thể cung cấp cho người dùng các kết quả tìm kiếm phù hợp và được cập nhật thường xuyên.
2.1 Làm thế nào Web Crawler hoạt động?
Web Crawler hoạt động bằng cách theo dõi các liên kết từ một trang web đến trang web khác. Khi một Web Crawler truy cập vào một trang web, nó đọc mã HTML của trang để xác định nội dung và cấu trúc của trang. Sau đó, nó sẽ tập hợp các trang web đã thu thập dữ liệu và theo các đường dẫn từ các trang web đó đến các trang web khác. Crawler lặp lại quá trình này cho mỗi trang nó gặp phải, xây dựng bản đồ của web và thu thập dữ liệu trên các trang mà nó truy cập. Do vậy, Web Crawler có thể lập chỉ mục tất cả trang web kể cả các trang web được kết nối từ các trang khác.
2.2 Tối ưu hóa công cụ tìm kiếm Crawl trang web của bạn như thế nào?
Để đảm bảo rằng trang web của bạn được crawl và lập chỉ mục đúng cách, bạn cần hiểu rõ Crawling là gì và sau đó tối ưu hóa nó cho các công cụ tìm kiếm. Điều này bao gồm một số bước như sau:
- Gửi một bản đồ trang web cho các công cụ tìm kiếm để giúp họ khám phá và lập chỉ mục các trang của bạn.
- Tối ưu hóa cấu trúc và điều hướng của trang web của bạn để giúp cho Web Crawler hoạt động dễ dàng hơn trong việc tìm kiếm và điều hướng các trang của bạn.
- Sử dụng tiêu đề và thẻ mô tả chứa các từ khóa {tiêu đề mô tả và các thẻ tiêu đề mô tả chứa các từ khóa} để giúp công cụ tìm kiếm hiểu nội dung, chủ đề của các bài viết trên website..
- Đảm bảo rằng trang web của bạn thân thiện với di động và có tốc độ tải trang nhanh, vì những yếu tố này có thể ảnh hưởng đến cách mà Web Crawler và trải nghiệm người dùng khi xem trang web của bạn.

3. Cách Ngăn Google Crawl Dữ Liệu Không Quan Trọng Trên Website
Có rất nhiều cách để ngăn Google Crawl các dữ liệu không quan trọng hay bạn không muốn Google quét đến, sau đây là một số phương pháp hiệu quả nhất:
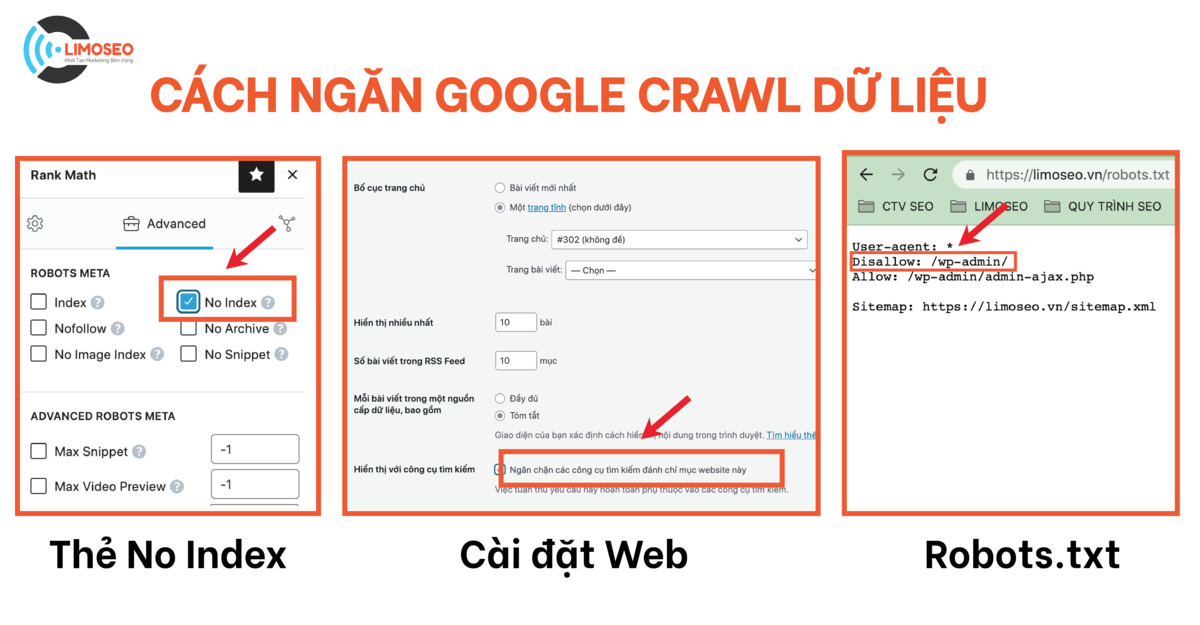
- Phương pháp đầu tiên và phổ biến nhất là sử dụng tệp robots.txt. Tệp robots.txt là tệp được đặt trong thư mục gốc của trang web của bạn, cho biết cho các công cụ tìm kiếm những trang nào trên trang web của bạn không nên được crawl dữ liệu. Đây có thể là một cách hữu ích để ngăn Google crawl các trang không quan trọng, chẳng hạn như trang đăng nhập, các biểu mẫu liên hệ hoặc trang kết quả tìm kiếm.
- Phương pháp thứ hai là tối ưu hóa cho ngân sách crawl. Ngân sách crawl đề cập đến lượng thời gian và tài nguyên mà Google cấp cho việc crawl trang web của bạn. Bạn có thể tối ưu hóa cho ngân sách crawl data bằng cách đảm bảo rằng trang web của bạn không có lỗi và thực hiện liên kết nội bộ để giúp Google đi đến hết các bài viết, các trang quan trọng trên website của bạn.
- Cuối cùng, bạn có thể sử dụng công cụ thông số URL trong Google Search Console để xác định những thông số nào sẽ bị bỏ qua bởi Google. Điều này đặc biệt hữu ích đối với các trang web sử dụng URL động với nhiều thông số, vì nó có thể giúp ngăn Google Crawl các nội dung trùng lặp hoặc không liên quan.
4. Crawler có thể bị gặp sự cố khi truy cập URL của bạn không?
Crawler có thể gặp sự cố khi truy cập vào một URL trên trang web của bạn. Điều này có thể xảy ra vì nhiều lý do khác nhau, chẳng hạn như lỗi máy chủ, trang web mất quá nhiều thời gian để tải hoặc trang web không tương thích với crawler.
Khi một crawler gặp sự cố, nó thường sẽ trả về mã trạng thái HTTP 4xx hoặc 5xx:
– Mã 4xx cho biết trang không thể được tìm thấy
– Mã 5xx cho biết có lỗi trên máy chủ.
Nếu trang web của bạn trả về mã 4xx hoặc 5xx, quan trọng là phải chẩn đoán và sửa chữa lỗi càng sớm càng tốt. Bạn có thể sử dụng các công cụ như Google Search Console để xác định trang nào đang trả về lỗi, sau đó làm việc với nhà phát triển web của bạn để khắc phục kịp thời.
5. Phân biệt Web Crawler và Web Scraper
Mặc dù thường được sử dụng thay thế nhau, tuy nhiên web crawler và web scraper thực sự là hai định nghĩa khác nhau. Web crawler là một chương trình tự động khám phá Internet tạo ra các Data Crawling, theo dõi các liên kết từ một trang web đến trang web tiếp theo và lập chỉ mục nội dung cho những trang đó. Crawler được sử dụng bởi các công cụ tìm kiếm như Google để tạo ra một chỉ mục của Internet, được sử dụng để tạo ra kết quả tìm kiếm.
Một web scraper, ngược lại, là một chương trình được thiết kế để trích xuất dữ liệu cụ thể từ một trang web. Scrapers thường được sử dụng bởi các nhà tiếp thị, các chuyên gia phân tích dữ liệu và các chuyên gia khác để thu thập dữ liệu cho phân tích, nghiên cứu hoặc mục đích khác.
Mặc dù cả crawler và scraper đều có thể là những công cụ hữu ích, tuy nhiên hiểu được sự khác biệt giữa chúng sẽ là yếu tố rất quan trọng giúp bạn sử dụng hiệu quả hơn. Nếu bạn đang tìm cách tối ưu hóa trang web của mình cho các công cụ tìm kiếm, bạn sẽ muốn tập trung vào đảm bảo rằng trang web của bạn dễ dàng được lập chỉ mục bởi Google và các công cụ tìm kiếm khác. Nếu bạn đang tìm cách thu thập dữ liệu từ một trang web, bạn có thể cần sử dụng scraper để trích xuất dữ liệu cụ thể bạn cần.

Tóm lại, việc crawling là một phần quan trọng trong quá trình SEO. Bằng cách đảm bảo rằng trang web của bạn được crawling dễ dàng bởi Google, sẽ giúp bạn cải thiện khả năng hiển thị trang web của mình trong kết quả tìm kiếm và tăng lượng traffic tự nhiên đến website hơn. Bài viết trên đã cung cấp các thông tin tổng quát, cần thiết nhất xung quanh chủ đề “Crawling là gì”, nếu có bất kỳ thắc mắc nào khác hãy liên hệ ngay đến Công Ty Quảng Cáo Marketing Online Limoseo để được hỗ trợ nhé!